
Fear, Uncertainty, and ...Utilization?
Using AI to See the Future, Increase Confidence, and Lower Kubernetes Costs

What’s Good?!
We’ve come a long way, y’all!
We all know the cloud has transformed what’s possible with computers. It’s paved a path of wild opportunity for business folk and nerds alike.
And speaking of shared interests between business folk and nerds, one of the flagship innovations of the cloud era is the idea of autoscaling – or, infrastructure that uses only what’s necessary – smartly provisioning and releasing compute on the fly, based on its needs.
The promise of autoscaling is to enable cost efficiency in exchange for an agreeable set of reliability tradeoffs, and it’s fair to say that the core of that promise has been delivered. Autoscaling patterns have become an industry best practice for any shop with a significant compute footprint and they’ve unlocked gross margins and SLAs that otherwise wouldn’t be possible.
The Elephant In The Room Tho
It’s true that the world is a better place thanks to autoscaling patterns.
Ok, so, yay! Right? So what is there to talk about??
Well, another innovation to emerge in the last twenty years is the engineering best practice of rapid iteration, continuous delivery and shipping the smallest useful thing. When done correctly, early iterations of a fully delivered product or feature will be far from perfect. And guess what – autoscaling is no exception! In my opinion, the autoscaling status quo leaves much to be desired and is ripe for iteration.
By the way, you have no idea how tempting it was to use a clickbait title like “autoscaling is broken,” 😅 because in my opinion, it wouldn’t be too far from the truth.
So what’s the issue?
The issue is fear, uncertainty, and utilization! Let’s dive in!
Utilization Realization
Google defines utilization as the percentage of a resource that is being used.
In essence, utilization is the percentage of your compute infrastructure actively servicing your business. Electrons carrying business value are flying across silicon chips at the speed of light!
Here’s where things start getting uncomfortable though. 😅
If utilization is the percentage of your infrastructure servicing your business, that means the inverse of your utilization is the percentage of your infrastructure doing absolutely nothing! Expensive cloud servers doing nothing but racking up your cloud bill!
Now pull out your phone and text your closest SRE friend and ask them what their autoscaling setup brings their infrastructure’s compute utilization to. I’d wager they’ll tell you somewhere between 40-60%.
Let’s look at the generous end. 60%.
A 60% utilization means that two out of five servers in the infrastructure are idling, doing nothing but costing money! 🤯
And most importantly, Jeff, Sundar, and Satya don’t consider the fact those servers aren’t being used – your ass is getting that invoice!
So for most shops, their production engineering world orbits the need to balance cost and reliability – ensuring the business has enough capacity to prevent downtime while not overspending.
So, autoscaling to the rescue. Right? Well, yeah, but…
Status Quo Woe
The thing is, as beautiful as it is that we can provision entire servers on-demand, scale events aren’t instantaneous. Provisioning new capacity can take anywhere from 30 seconds to twenty minutes!
This is the reason the industry standard utilization target is between 40-60%. Let’s break it down.
Scaling in real time means you always need enough extra room to handle new demand while new compute spins up. The extra capacity you keep on hand should be enough to cover how fast usage is growing, multiplied by how long it takes to spin up that new compute. The formula looks something like this:
C = total current capacity
r = rate of usage increase (units per second) ← the scary r monster. Remember this for later
t = time to provision new capacity (seconds)
U = target utilization percentage
Spare Capacity (SC) = C × (1−U)
SC ≥ r × t
Real time autoscaling is essentially the idea of balancing cost versus reliability using this formula, and, most importantly for this discussion, making educated guesses about the likely nature and risks of future r. Let’s say it again:
Making educated guesses about the likely nature and risks of future r
The big scary r monster.
This is where things start to get interesting. 🍿
You’re managing risk. You don’t know what r is going to be in the future. And your risk tolerance is determined by how high you think r could realistically be and how likely it could go there in the worst case scenario. If spare capacity (SC) isn’t large enough to support r, you risk an outage. So your risk tolerance is ultimately what you use to decide U (your utilization percentage), which puts SC where it needs to be for you to keep your job.
Worried about risk? Lower utilization percentage U. Less worried? You can target higher utilization.
Fear and uncertainty about r is what brings us to such a wasteful status quo (40-60%) for utilization targets. We have to reconcile the fact we can’t see the future with being partial to steady paychecks!
We Have The Technology!
But there’s good news: we have the technology to address this problem! We can use AI to analyze historical usage and make accurate predictions of the future of r that give us greatly increased confidence in what it will be! Y’all! It’s hard to overstate how much this matters!
When you’re confident of what r will be, you can be confident you’ll have the necessary capacity ready when the time comes, whatever r ends up being. That means there’s less of a need for expensive just-in-case servers doing nothing 100% of the time.
And when we’re no longer living in fear and uncertainty of the future of r, we can target more aggressive utilization rates!
…And with higher utilization rates comes higher gross margins!
Here’s an example:
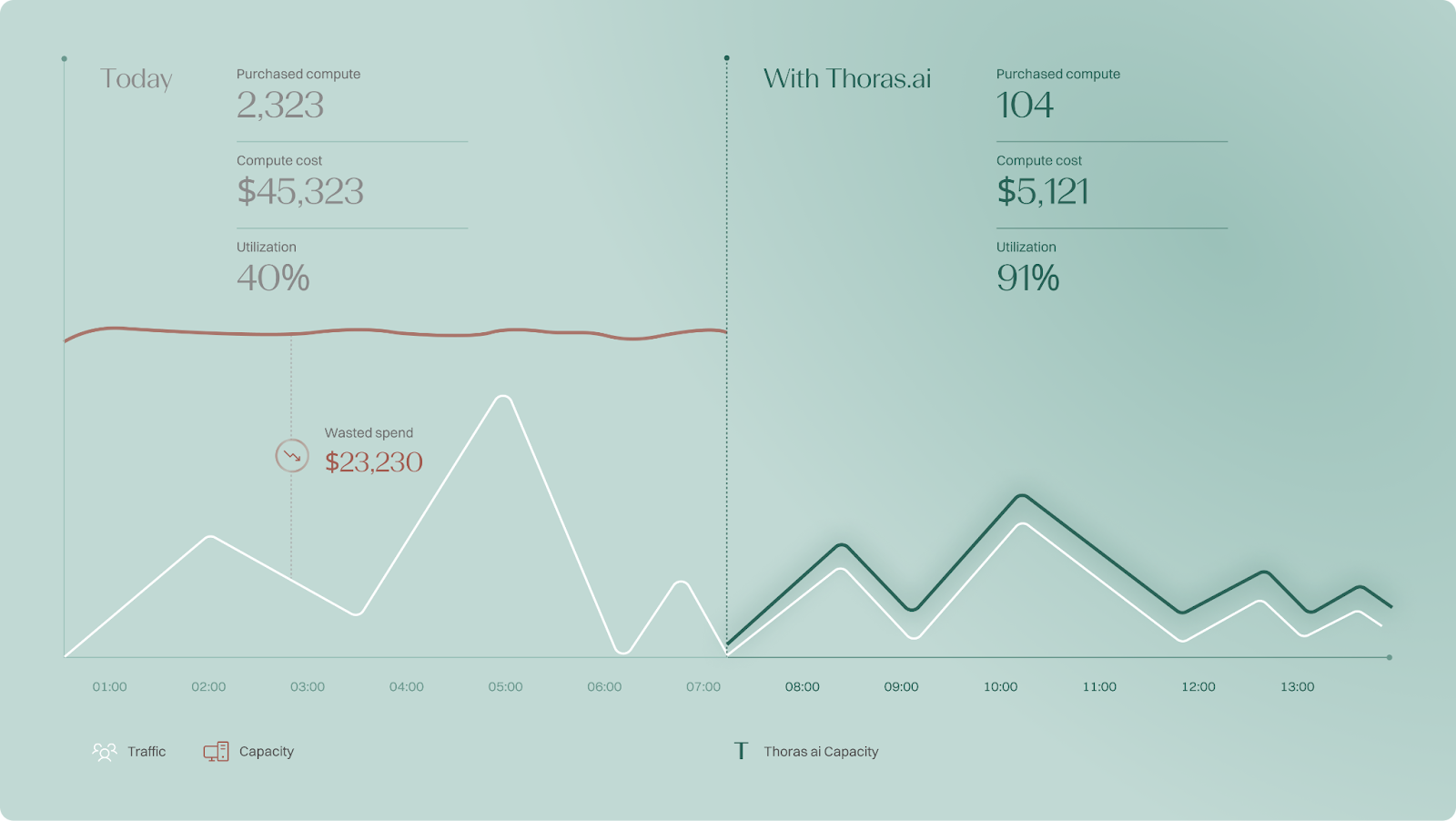
Let’s put it this way:
If your compute bill is $100k/month and you used your newly increased confidence in r to increase utilization from 60% → 80%, you will have saved your business almost a quarter million dollars that year! Let’s friggin’ go!
Check Us Out!
Interested in boosting confidence and saving money by scaling on future usage? Hit us up at info@thoras.ai and try out Thoras for free! We’d love to hear from you!